Implementación de PySpark Microservice en Kubernetes: revolucionando los lagos de datos con Ilum.

¡Saludos entusiastas de Ilum y fanáticos de Python! Estamos encantados de presentar una nueva característica muy esperada que potenciará su viaje de ciencia de datos: soporte completo de Python en Ilum. Para aquellos en el mundo de los datos, Python y Apache Spark han sido durante mucho tiempo un dúo icónico, que maneja sin problemas grandes volúmenes de datos y cálculos complejos. Y ahora, con la última actualización de Ilum, puede aprovechar el poder de Python directamente dentro de su entorno de lago de datos favorito.
Esta publicación de blog es su recorrido guiado para explorar esta función. Comenzaremos con un trabajo simple de Apache Spark escrito en Python, lo ejecutaremos en Ilum y luego profundizaremos más. Transformaremos el código inicial para que admita un modo interactivo, ofreciéndote acceso directo al trabajo de Spark a través de la API de Ilum. Al final de este viaje, tendrá un microservicio basado en Python que responde a las llamadas a la API, todo funcionando sin problemas en Ilum.
Entonces, ¿estás listo para mejorar tu juego de datos con Python e Ilum? Empecemos.
Todos los ejemplos están disponibles en nuestro Repositorio de GitHub .
Paso 1: Escribir un trabajo simple de Apache Spark en Python.
Antes de embarcarnos en nuestro viaje de Python con Ilum, debemos asegurarnos de que nuestro entorno esté bien equipado. Para ejecutar un trabajo de Spark, debe tener instalados Ilum y PySpark. Puede usar pip, el instalador de paquetes de Python, para configurar PySpark. Asegúrate de que estás usando Python >=3.9.
pip instalar pyspark Para configurar y acceder a Ilum, siga las pautas proporcionadas aquí .
1.1 Ejemplo de SparkPi.
Ahora, profundicemos en la escritura de nuestro trabajo de Spark. Comenzaremos con un ejemplo simple de SparkPi
Importar sistema
De Random Import Random
Desde el operador import add
desde pyspark.sql importar SparkSession
if __name__ == "__main__":
chispa = SparkSession \
.constructor\
.appName("PythonPi") \
.getOrCreate()
particiones = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * particiones
def f(_: int) -> float:
x = aleatorio() * 2 - 1
y = aleatorio() * 2 - 1
return 1 si x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi es aproximadamente %f" % (4.0 * count / n))
chispa.stop() Guarde este script como ilum_python_simple.py
Con nuestro trabajo de Spark listo, es hora de ejecutarlo en Ilum. Ilum ofrece la capacidad de enviar trabajos utilizando la interfaz de usuario de Ilum o a través de la API REST.
Comencemos con la interfaz de usuario con el método Característica de un solo trabajo.
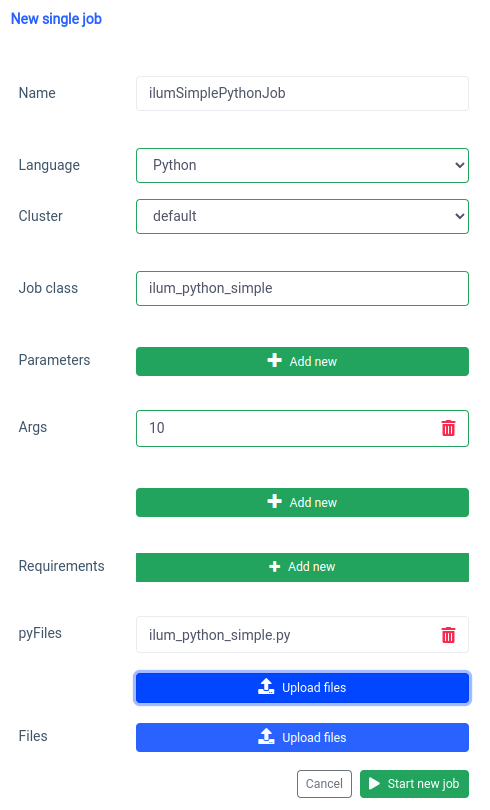
Podemos lograr lo mismo con el API , pero primero, necesitamos exponer la API ilum-core con reenvío de puertos.
kubectl port-forward svc/ilum-core 9888:9888 Con el puerto expuesto podemos hacer una llamada a la API.
curl -X POST 'localhost:9888/api/v1/job/submit' \
--form 'name="ilumSimplePythonJob"' \
--form 'clusterName="default"' \
--form 'jobClass="ilum_python_simple"' \
--form 'args="10"' \
--form 'pyFiles=@"/ruta/a/ilum_python_simple.py"' \
--form 'language="PYTHON"' Llamada a la API
Como resultado, recibiremos el id del trabajo creado.
{"jobId":"20230724-1154-m78f3gmlo5j"} Resultado
Para comprobar los logs del trabajo podemos hacer una llamada a la API
curl localhost:9888/api/v1/job/20230724-1154-m78f3gmlo5j/logs Llamada a la API
¡Y eso es todo! Ha escrito y ejecutado un trabajo sencillo de Python Spark en Ilum. Veamos un ejemplo un poco más avanzado que necesita bibliotecas de Python adicionales.
1.2 Ejemplo de trabajo con numpy.
En esta sección, repasaremos un ejemplo práctico de un trabajo de Spark escrito en Python. Este trabajo implica leer un conjunto de datos, procesarlo, entrenar un modelo de aprendizaje automático en él y guardar las predicciones. Vamos a usar un Tel-churn.csv archivo, que puedes encontrar en nuestro Repositorio de GitHub . Para facilitar las cosas, hemos subido este archivo a un bucket llamado ilum-files en la instancia integrada de MinIO, al que se puede acceder automáticamente desde la instancia de Ilum. Esto significa que no tendrá que preocuparse por configurar ningún acceso para este ejemplo: Ilum lo tiene cubierto. Sin embargo, si alguna vez desea obtener datos de un bucket diferente o utilizar Amazon S3 en sus propios proyectos, deberá configurar los accesos en consecuencia.
Ahora que tenemos nuestros datos listos, comencemos a escribir nuestro trabajo de Spark en Python. Este es el ejemplo de código completo:
desde pyspark.sql importar SparkSession
de pyspark.ml Pipeline de importación
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.classification import LogisticRegression
if __name__ == "__main__":
chispa = SparkSession \
.constructor\
.appName("IlumAdvancedPythonExample") \
.getOrCreate()
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True)
categoricalColumns = ['género', 'Socio', 'Dependientes', 'Serviciotelefónico', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV',
'StreamingMovies', 'Contrato', 'PaperlessBilling', 'PaymentMethod']
etapas = []
para categoricalCol en categoricalColumns:
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
stages += [stringIndexer]
label_stringIdx = StringIndexer(inputCol="Churn", outputCol="label")
etapas += [label_stringIdx]
numericCols = ['SeniorCitizen', 'tenencia', 'MonthlyCharges']
assemblerInputs = [c + "Índice" para c en categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
Etapas += [ensamblador]
pipeline = Pipeline(stages=stages)
pipelineModel = pipeline.fit(df)
df = pipelineModel.transform(df)
entrenar, prueba = df.randomSplit([0.7, 0.3], semilla = 42)
lr = LogisticRegression(featuresCol="features", labelCol="label", maxIter=10)
lrModel = lr.fit(tren)
predicciones = lrModel.transform(prueba)
predictions.select("customerID", "label", "prediction").show(5)
predictions.select("customerID", "label", "prediction").write.option("header", "true") \
.csv('s3a://ilum-files/predictions')
chispa.stop() Profundicemos en el código:
desde pyspark.sql importar SparkSession
de pyspark.ml Pipeline de importación
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.classification import LogisticRegression Aquí, importamos los módulos de PySpark necesarios para crear una sesión de Spark, crear una canalización de aprendizaje automático, preprocesar los datos y ejecutar un modelo de regresión logística.
chispa = SparkSession \
.constructor\
.appName("IlumAdvancedPythonExample") \
.getOrCreate() Inicializamos un archivo SparkSession , que es el punto de entrada a cualquier funcionalidad de Spark. Aquí es donde establecemos el nombre de la aplicación que aparecerá en la interfaz de usuario web de Spark.
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True) Estamos leyendo un archivo CSV almacenado en un cubo minio. El header=Verdadero le dice a Spark que use la primera fila del archivo CSV como encabezados, mientras que inferSchema=Verdadero hace que Spark determine automáticamente el tipo de datos de cada columna.
categoricalColumns = ['género', 'Socio', 'Dependientes', 'Serviciotelefónico', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV',
'StreamingMovies', 'Contrato', 'PaperlessBilling', 'PaymentMethod'] Especificamos las columnas de nuestros datos que son categóricas. Estos se transformarán más adelante mediante un StringIndexer.
etapas = []
para categoricalCol en categoricalColumns:
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
stages += [stringIndexer] Aquí, estamos recorriendo en iteración nuestra lista de columnas categóricas y creando un StringIndexer para cada una. StringIndexers codifica columnas de cadena categóricas en una columna de índices. La columna de índice transformada se denominará como el nombre de columna original anexado con "Índice".
numericCols = ['SeniorCitizen', 'tenencia', 'MonthlyCharges']
assemblerInputs = [c + "Índice" para c en categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
Etapas += [ensamblador] Aquí preparamos los datos para nuestro modelo de aprendizaje automático. Creamos un VectorAssembler que tomará todas nuestras columnas de características (tanto categóricas como numéricas) y las ensamblará en una sola columna vectorial. Este es un requisito para la mayoría de los algoritmos de aprendizaje automático en Spark.
entrenar, prueba = df.randomSplit([0.7, 0.3], semilla = 42) Dividimos nuestros datos en un conjunto de entrenamiento y un conjunto de prueba, con el 70 % de los datos para el entrenamiento y el 30 % restante para las pruebas.
lr = LogisticRegression(featuresCol="features", labelCol="label", maxIter=10)
lrModel = lr.fit(tren) Entrenamos un modelo de regresión logística con nuestros datos de entrenamiento.
predicciones = lrModel.transform(prueba)
predictions.select("customerID", "label", "prediction").show(5)
predictions.select("customerID", "label", "prediction").write.option("header", "true") \
.csv('s3a://ilum-files/predictions') Por último, usamos nuestro modelo entrenado para hacer predicciones en nuestro conjunto de pruebas, mostrando las primeras 5 predicciones. A continuación, escribimos estas predicciones en nuestro cubo minio.
Guarde este script como ilum_python_advanced.py
pyspark.ml usa numpy como una dependencia, que no está instalada de forma predeterminada, por lo que debemos especificarla como un requisito.
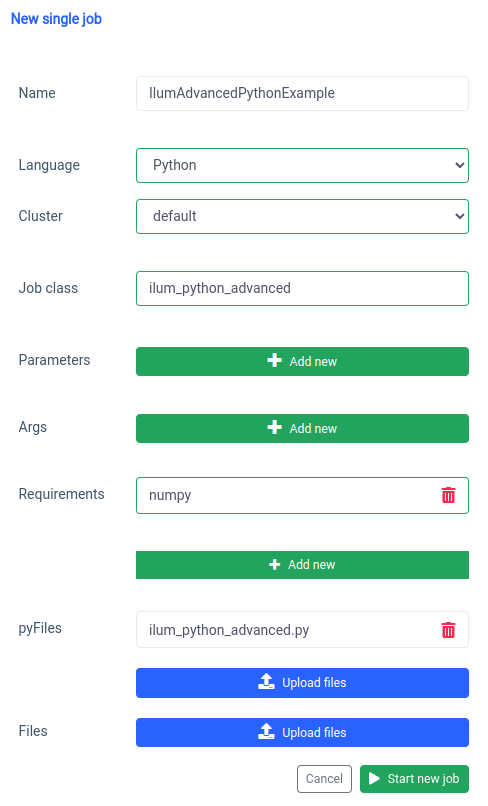
Y lo mismo se puede hacer a través de la API.
curl -X POST 'localhost:9888/api/v1/job/submit' \
--form 'name="IlumAdvancedPythonExample"' \
--form 'clusterName="default"' \
--form 'jobClass="ilum_python_advanced"' \
--form 'pyRequirements="numpy"' \
--form 'pyFiles=@"/ruta/a/ilum_python_advanced.py"' \
--form 'language="PYTHON"' Llamada a la API
En las siguientes secciones, transformaremos ambos scripts de Python en un interactivo Spark job, aprovechando al máximo las capacidades de Ilum.
Paso 2: Transición al modo interactivo
El modo interactivo es una característica interesante que hace que el desarrollo de Spark sea más dinámico, ya que le brinda la capacidad de ejecutar, interactuar y controlar sus trabajos de Spark en tiempo real. Está diseñado para aquellos que buscan un control más directo sobre sus aplicaciones Spark.
Piensa en el modo interactivo como tener una conversación directa con tu trabajo de Spark. Puede introducir datos, solicitar transformaciones y obtener resultados, todo en tiempo real. Esto mejora drásticamente la agilidad y la capacidad de su proceso de procesamiento de datos, lo que lo hace más adaptable y responde a los requisitos cambiantes.
Ahora que estamos familiarizados con la creación de un trabajo básico de Spark en Python, vayamos un paso más allá transformando nuestro trabajo en uno interactivo que pueda aprovechar las capacidades en tiempo real de Ilum.
2.1 Ejemplo de SparkPi.
Para ilustrar cómo hacer la transición de nuestro trabajo al modo interactivo, ajustaremos nuestro ilum_python_simple.py Guión.
De Random Import Random
Desde el operador import add
de ilum.api importar IlumJob
clase SparkPiInteractiveExample(IlumJob):
def run(self, spark, config):
particiones = int(config.get('particiones', '5'))
n = 100000 * particiones
def f(_: int) -> float:
x = aleatorio() * 2 - 1
y = aleatorio() * 2 - 1
return 1 si x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
return "Pi es aproximadamente %f" % (4.0 * count / n) Guarde esto como ilum_python_simple_interactive.py
Solo hay algunas diferencias con el SparkPi original.
1. Paquete Ilum
Para empezar, importamos el archivo IlumJob class del paquete ilum, que sirve como clase base para nuestro trabajo interactivo.
La lógica de trabajo de Spark se encapsula en una clase que se extiende IlumJob , en particular en el marco de su correr método. Podemos añadir el paquete ilum con:
pip install ilum 2. Trabajo de Spark en una clase
La lógica de trabajo de Spark se encapsula en una clase que se extiende IlumJob , en particular en el marco de su correr método.
clase SparkPiInteractiveExample(IlumJob):
def run(self, spark, config):
# Lógica de trabajo aquí Envolver la lógica del trabajo en una clase es esencial para que el marco de Ilum maneje el trabajo y sus recursos. Esto también hace que el trabajo no tenga estado y sea reutilizable.
3. Los parámetros se manejan de manera diferente:
Estamos tomando todos los argumentos del diccionario de configuración
particiones = int(config.get('particiones', '5')) Este cambio permite un paso de parámetros más dinámicos y se integra con el manejo de la configuración de Ilum.
4. El resultado se devuelve en lugar de imprimirse:
El resultado se devuelve desde el archivo correr método.
return "Pi es aproximadamente %f" % (4.0 * count / n) Al devolver el resultado, Ilum puede manejarlo de una manera más flexible. Por ejemplo, Ilum podría serializar el resultado y hacerlo accesible a través de una llamada API.
5. No es necesario administrar manualmente la sesión de Spark
Ilum gestiona la sesión de Spark por nosotros. Se inyecta automáticamente en el correr y no necesitamos detenerlo manualmente.
def run(self, spark, config): Estos cambios resaltan la transición de un trabajo de Spark independiente a un trabajo de Ilum interactivo. El objetivo es mejorar la flexibilidad y la reutilización del trabajo, haciéndolo más adecuado para cálculos dinámicos, interactivos y sobre la marcha.
La adición de un trabajo de Spark interactivo se maneja con la función 'nuevo grupo'.
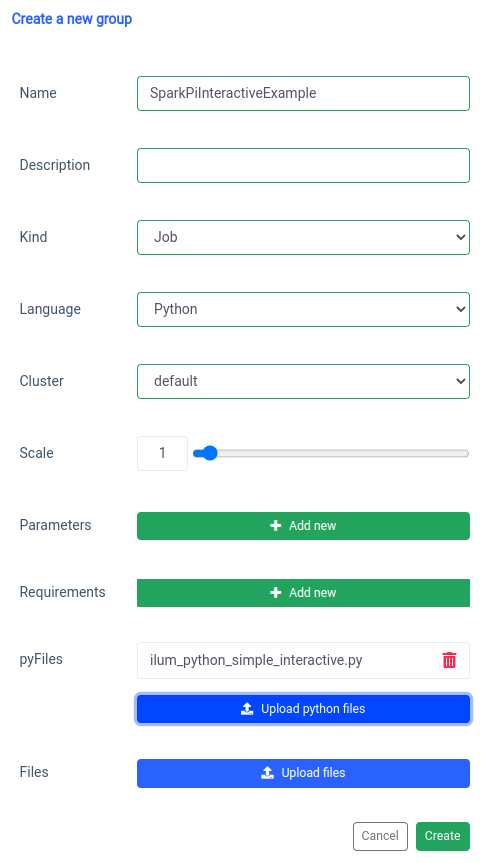
Y la ejecución con la función de trabajo interactivo en la interfaz de usuario.
El nombre de la clase debe especificarse como un pythonFileName.PythonClassImplementingIlumJob
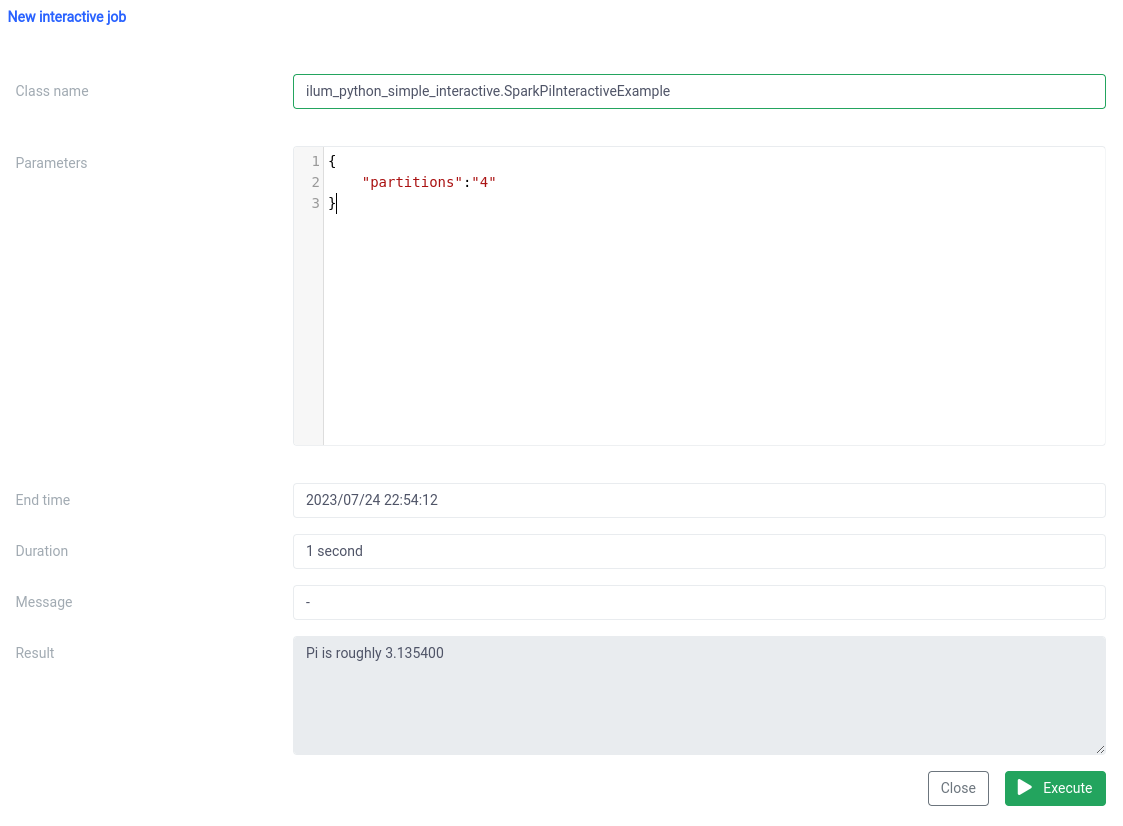
Podemos lograr lo mismo con el API .
1. Creación de grupo
curl -X POST 'localhost:9888/api/v1/group' \
--form 'name="SparkPiInteractiveExample"' \
--form 'kind="TRABAJO"' \
--form 'clusterName="default"' \
--form 'pyFiles=@"/ruta/a/ilum_python_simple_interactive.py"' \
--form 'language="PYTHON"' Llamada a la API
{"groupId":"20230726-1638-mjrw3"} Resultado
2. Ejecución del trabajo
curl -X POST 'localhost:9888/api/v1/group/20230726-1638-mjrw3/job/execute' \
-h 'Tipo-de-contenido: application/json' \
-d '{ "jobClass":"ilum_python_simple_interactive. SparkPiInteractiveExample", "jobConfig": {"partitions":"10"}, "type":"interactive_job_execute"}' Llamada a la API
{
"jobInstanceId":"20230726-1638-mjrw3-a1srahhu",
"jobId":"20230726-1638-mjrw3-wwt5a",
"groupId":"20230726-1638-mjrw3",
"startTime":1690390323154,
"endTime":1690390325200,
"jobClass":"ilum_python_simple_interactive. SparkPiInteractiveExample",
"jobConfig":{
"particiones":"10"
},
"result":"Pi es aproximadamente 3.149400",
"error":null
} Resultado
2.2 Ejemplo de trabajo con numpy.
Veamos nuestro segundo ejemplo.
desde pyspark.sql importar SparkSession
de pyspark.ml Pipeline de importación
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml.classification import LogisticRegression
de ilum.api importar IlumJob
class LogisticRegressionJobExample(IlumJob):
def run(self, spark_session: SparkSession, config: dict) -> str:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=True,
inferSchema=Verdadero)
categoricalColumns = ['género', 'Socio', 'Dependientes', 'Serviciotelefónico', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV',
'StreamingMovies', 'Contrato', 'PaperlessBilling', 'PaymentMethod']
etapas = []
para categoricalCol en categoricalColumns:
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
stages += [stringIndexer]
label_stringIdx = StringIndexer(inputCol="Churn", outputCol="label")
etapas += [label_stringIdx]
numericCols = ['SeniorCitizen', 'tenencia', 'MonthlyCharges']
assemblerInputs = [c + "Índice" para c en categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
Etapas += [ensamblador]
pipeline = Pipeline(stages=stages)
pipelineModel = pipeline.fit(df)
df = pipelineModel.transform(df)
entrenar, probar = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))],
seed=int(config.get('semilla', '42')))
lr = LogisticRegression(featuresCol="features", labelCol="label", maxIter=int(config.get('maxIter', '5')))
lrModel = lr.fit(tren)
predicciones = lrModel.transform(prueba)
return '{}'.format(predictions.select("customerID", "label", "prediction").limit(
int(config.get('rowLimit', '5'))).toJSON().collect()) 1. Envolvemos el trabajo en una clase, al igual que en el ejemplo anterior:
class LogisticRegressionJobExample(IlumJob):
def run(self, spark_session: SparkSession, config: dict) -> str:
# Lógica de trabajo aquí De nuevo, la lógica del trabajo se encapsula en el archivo correr método de una clase que se extiende IlumJob , ayudando a Ilum a manejar el trabajo de manera eficiente.
2. Todos los parámetros, incluidos los de la canalización de datos (como las rutas de acceso de los archivos y los hiperparámetros de regresión logística), se obtienen de la config diccionario:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=True, inferSchema=True)
train, test = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))], seed=int(config.get('seed', '42')))
lr = LogisticRegression(featuresCol="features", labelCol="label", maxIter=int(config.get('maxIter', '5'))) Al centralizar todos los parámetros en un solo lugar, Ilum proporciona una forma uniforme y coherente de configurar y ajustar el trabajo.
El resultado del trabajo, en lugar de escribirse en una ubicación específica, se devuelve como una cadena JSON:
return '{}'.format(predictions.select("customerID", "label", "prediction").limit(int(config.get('rowLimit', '5'))).toJSON().collect()) Esto permite un manejo más dinámico y flexible del resultado del trabajo, que luego podría procesarse más o exponerse a través de una API, según las necesidades de la aplicación.
Este código muestra perfectamente cómo podemos integrar sin problemas los trabajos de PySpark con Ilum para permitir canalizaciones de procesamiento de datos interactivas y basadas en API. Desde ejemplos simples como la aproximación de Pi hasta casos más complejos como la regresión logística, los trabajos interactivos de Ilum son versátiles, adaptables y eficientes.
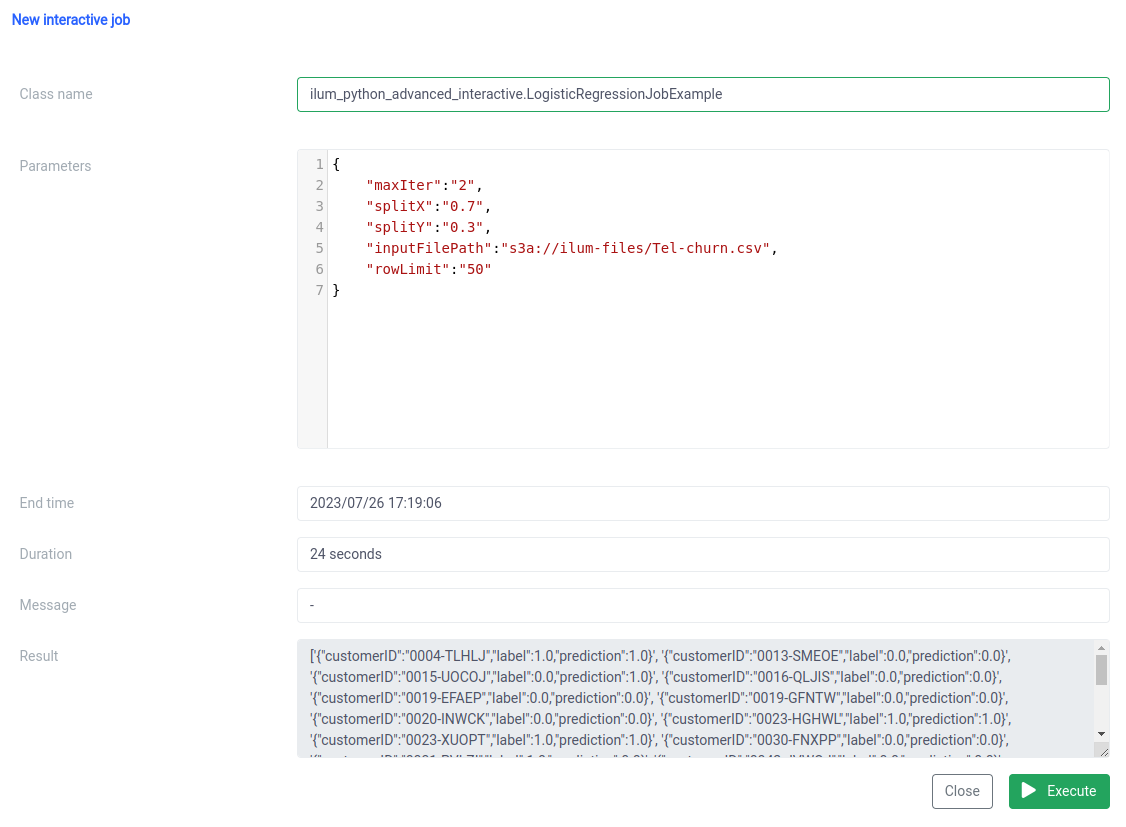
Paso 3: Convertir el trabajo de Spark en un microservicio
Los microservicios aportan un cambio de paradigma de la estructura de aplicación monolítica tradicional a un enfoque más modular y ágil. Al dividir una aplicación compleja en servicios pequeños y poco acoplados, resulta más fácil crear, mantener y escalar cada servicio de forma independiente en función de requisitos específicos. Cuando se aplica a nuestro trabajo de Spark, esto significa que podríamos crear un servicio de procesamiento de datos sólido que podría escalarse, administrarse y actualizarse sin afectar a otras partes de nuestra pila de aplicaciones.
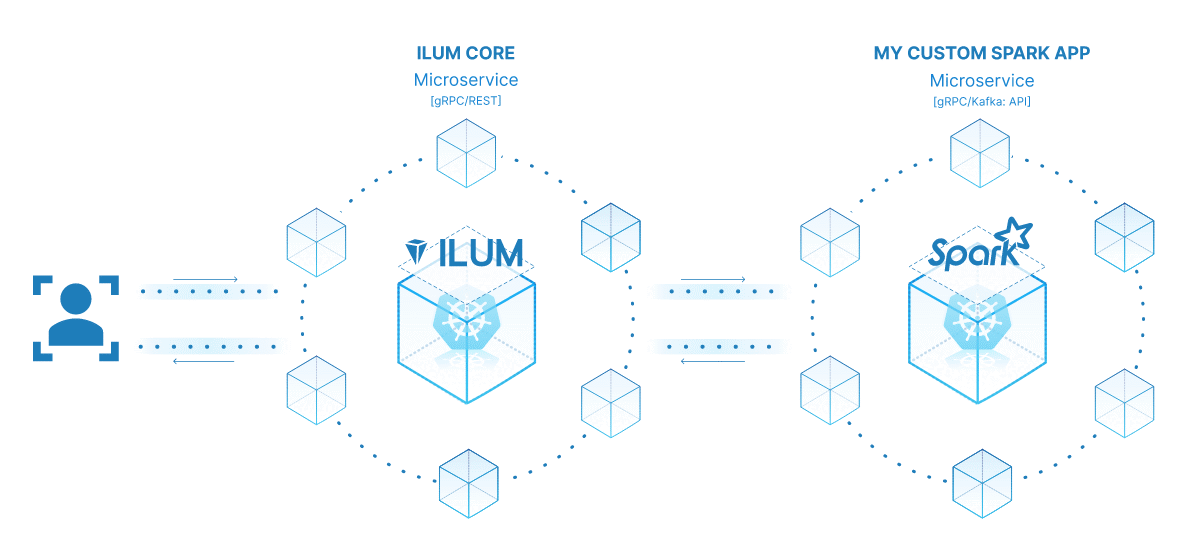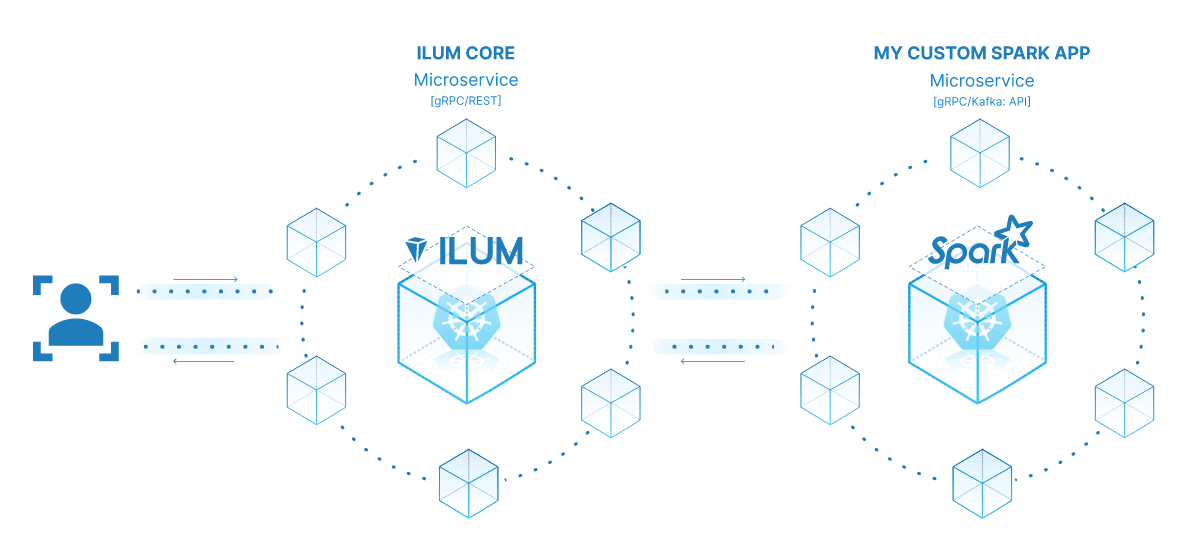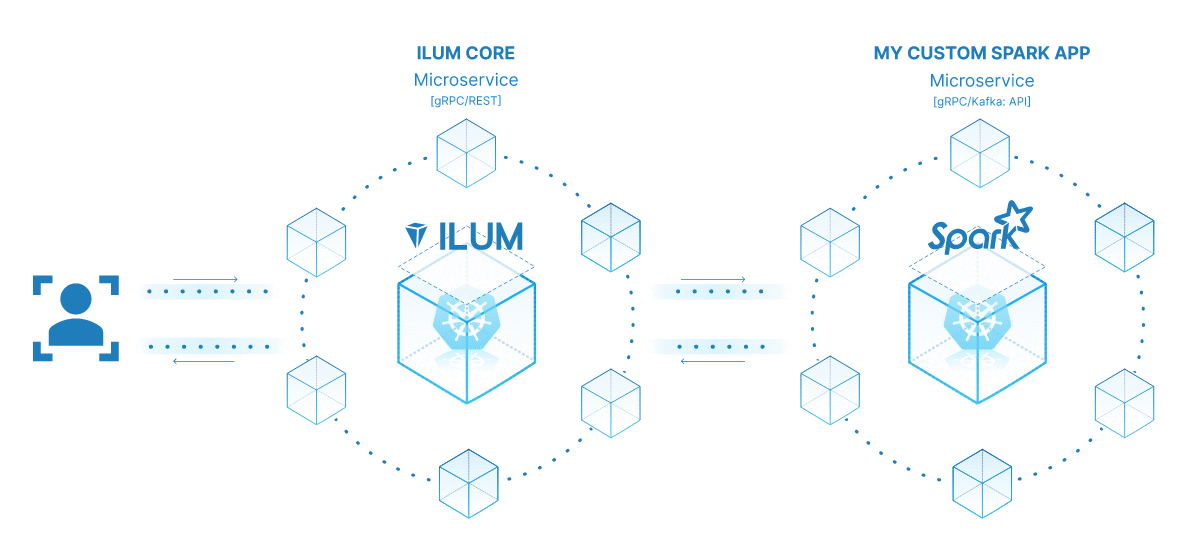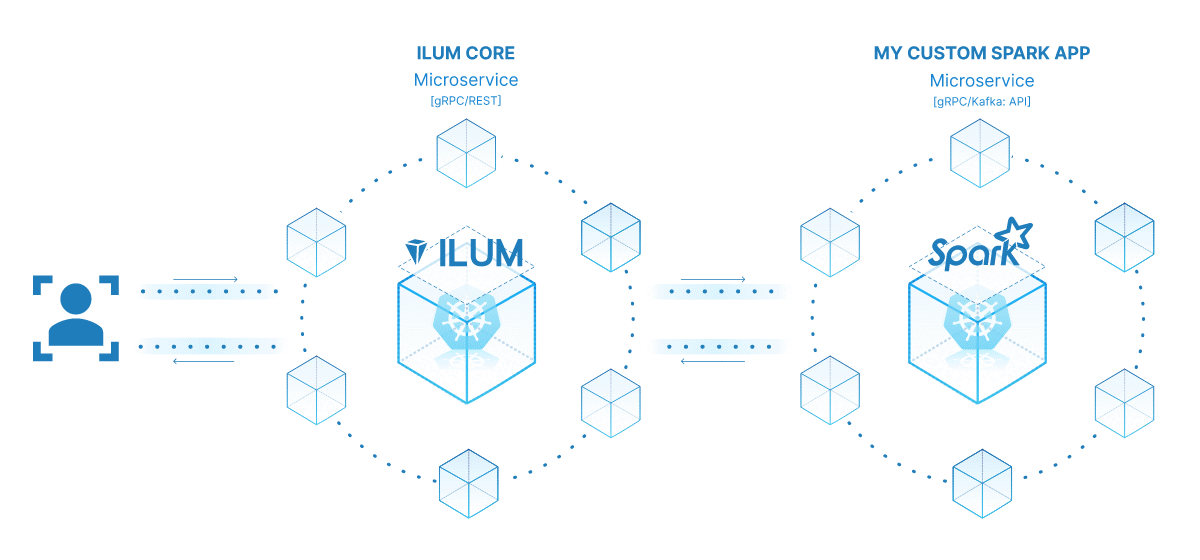
El poder de convertir su trabajo de Spark en un microservicio radica en su versatilidad, escalabilidad y capacidades de interacción en tiempo real. Un microservicio es un componente que se puede implementar de forma independiente de una aplicación que se ejecuta como un proceso independiente. Se comunica con otros componentes a través de API bien definidas, lo que le da la libertad de diseñar, desarrollar, implementar y escalar cada microservicio de forma independiente.
En el contexto de Ilum, un trabajo interactivo de Spark se puede tratar como un microservicio. El método "run" del trabajo actúa como un punto de conexión de la API. Cada vez que llamas a este método a través de la API de Ilum, estás haciendo una solicitud a este microservicio. Esto abre la posibilidad de interacciones en tiempo real con el trabajo de Spark.
Puede realizar solicitudes a su microservicio desde varias aplicaciones o scripts, obtener datos y procesar los resultados sobre la marcha. Además, abre la oportunidad de crear arquitecturas más complejas y orientadas a servicios en torno a sus canalizaciones de procesamiento de datos.
Una ventaja clave de esta configuración es la escalabilidad. A través de la interfaz de usuario o la API de Ilum, puede escalar o reducir su trabajo (microservicio) en función de la carga o la complejidad informática. No tiene que preocuparse por la administración manual de recursos o el equilibrio de carga. El equilibrador de carga interno de Ilum distribuirá las llamadas a la API entre las instancias de su trabajo de Spark, lo que garantiza una utilización eficiente de los recursos.
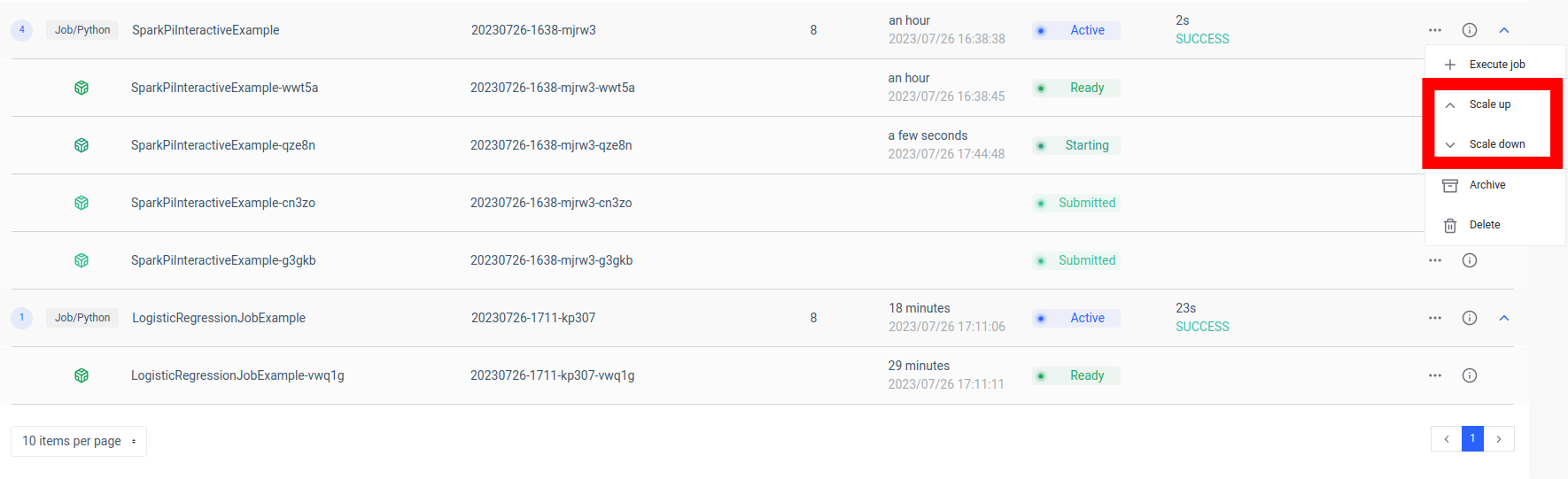
Tenga en cuenta que el tiempo de procesamiento real del trabajo depende de la complejidad del trabajo de Spark y de los recursos asignados a él. Sin embargo, con la escalabilidad proporcionada por Kubernetes, puede escalar fácilmente sus recursos a medida que crecen los requisitos de su trabajo.
Esta combinación de Ilum, Apache Spark y microservicios ofrece una nueva forma ágil de procesar sus datos: ¡de manera eficiente, escalable y receptiva!

El punto de inflexión en la arquitectura de microservicios de datos
Hemos recorrido un largo camino desde que comenzamos este viaje de transformación de un simple trabajo de Python Apache Spark en un microservicio completo con Ilum. Vimos lo fácil que era escribir un trabajo de Spark, adaptarlo para que funcionara en modo interactivo y, en última instancia, exponerlo como un microservicio con la ayuda de la sólida API de Ilum. En el camino, aprovechamos el poder de Python, las capacidades de Apache Spark y la flexibilidad y escalabilidad de Ilum. Esta combinación no solo ha transformado nuestras capacidades de procesamiento de datos, sino que también ha cambiado la forma en que pensamos sobre la arquitectura de datos.
El viaje no se detiene aquí. Con soporte completo para Python en Ilum, se abre un nuevo mundo de posibilidades para el procesamiento y análisis de datos. A medida que continuamos construyendo y mejorando Ilum, estamos entusiasmados con las posibilidades futuras que Python trae a nuestra plataforma. Creemos que con Python e Ilum juntos, estamos solo al comienzo de la redefinición de lo que es posible en el mundo de la arquitectura de microservicios de datos.
¡Únase a nosotros en este emocionante viaje y demos forma juntos al futuro del procesamiento de datos!