How to run Apache Spark on Kubernetes in less than 5min

Tools like Ilum will go a long way in simplifying the process of installing Apache Spark on Kubernetes. This guide will take you through, step by step, how to run Spark well on your Kubernetes cluster. With Ilum, deploying, managing, and scaling Apache Spark clusters is easily and naturally done.
Introduction
Today, we will showcase how to get up and running with Apache Spark on K8s. There are many ways to do that, but most are complex and require several configurations. We will use Ilum since that will do all the cluster setup for us. In the next blog post, we will compare the usage with the Spark operator.
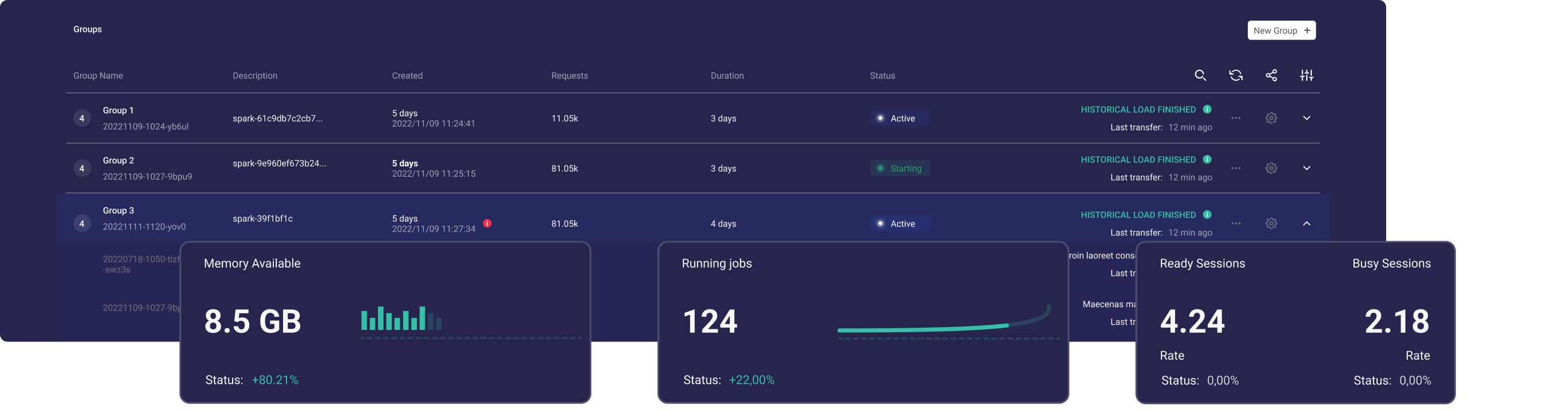
Ilum is a free, modular data lakehouse to easily deploy and manage Apache Spark clusters. It has a simple API to define and manage Spark, it will handle all dependencies. It helps with the creation of your own managed spark.
With Ilum, you can deploy Spark clusters in minutes and get started immediately running Spark applications. Ilum allows you to easily scale out and in your Spark clusters, managing multiple Spark clusters from a single UI.
With Ilum, getting started is easy if you are relatively new to Apache Spark on Kubernetes.
Step-by-Step Guide to Install Apache Spark on Kubernetes
Quick start
We assume that you have a Kubernetes cluster up and running, just in case you don't, check out these instructions to set up a Kubernetes cluster on the minikube. Check how to install minikube.
Setup a local kubernetes cluster
- Install Minikube: Execute the following command to install Minikube along with the recommended resources. This will install Minikube with 6 vCPUs and 12288 MB memory including the metrics server add-on that is necessary for monitoring.
minikube start --cpus 6 --memory 12288 --addons metrics-serverOnce you have a running Kubernetes cluster, it is just a few commands away to install Ilum:
Install Spark on Kubernetes with Ilum
helm repo add ilum https://charts.ilum.cloud- Install Ilum in Your Cluster
Here we have a few options.
a) The recommended one is to start with a few additional modules turned on (Data Lineage, SQL, Data Catalog).
helm install ilum ilum/ilum \
--set ilum-hive-metastore.enabled=true \
--set ilum-core.metastore.enabled=true \
--set ilum-sql.enabled=true \
--set ilum-core.sql.enabled=true \
--set global.lineage.enabled=trueb) you can also start with the most basic option which has only Spark and Jupyter notebooks.
helm install ilum ilum/ilumc) there is also an option to use ilum's module selection tool here.
minikube ssh docker pull ilum/core:6.6.0
This setup should take around two minutes. Ilum will deploy into your Kubernetes cluster, preparing it to handle Spark jobs.
Once the Ilum is installed, you can access the UI with port-forward and localhost:9777.
- Port Forward to Access UI: Use Kubernetes port-forwarding to access the Ilum UI.
kubectl port-forward svc/ilum-ui 9777:9777
Use admin/admin as default credentials. You can change them during the deployment process.
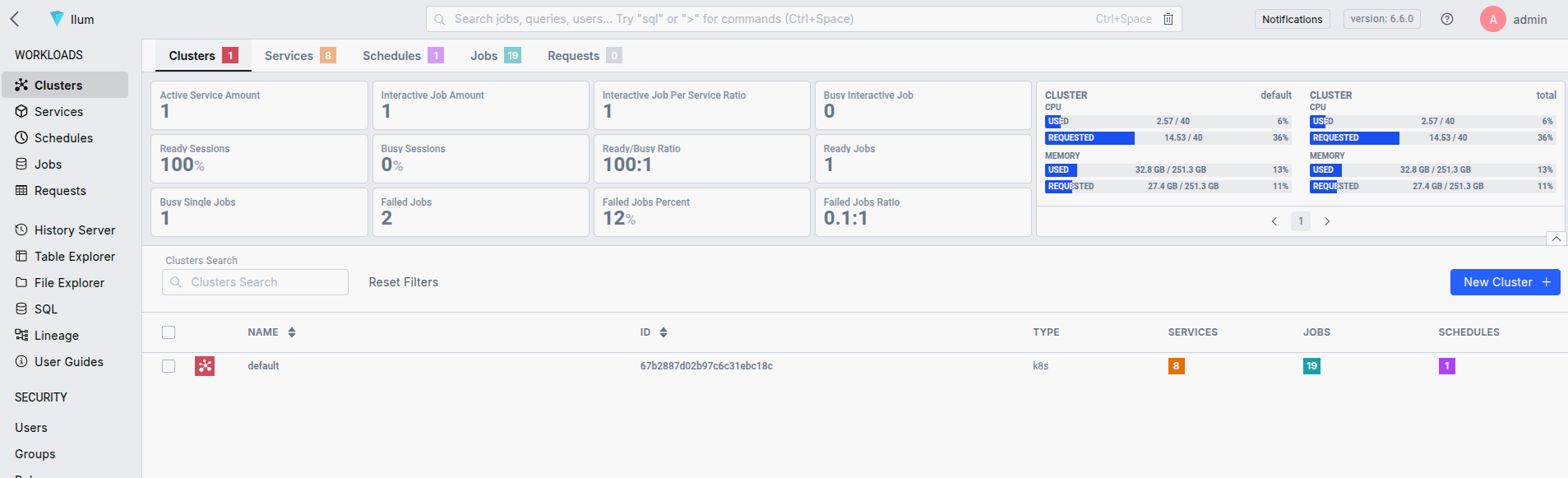
That’s all, your kubernetes cluster is now configured to handle spark jobs. Ilum provides a simple API and UI that makes it easy to submit Spark applications. You can also use the good old spark submit.
Deploy spark application on kubernetes
Let’s now start a simple spark job. We'll use the "SparkPi" example from the Spark documentation. You can use the jar file from this link.
ilum add spark job
Ilum will create a Spark driver kubernetes pod, it uses spark version 3.x docker image. You can control the number of spark executor pods by scaling them to multiple nodes. That's the simplest way to submit spark applications to K8s.

Running Spark on Kubernetes is really easy and frictionless with Ilum. It will configure your whole cluster and present you with an interface where you can manage and monitor your Spark cluster. We believe spark apps on Kubernetes are the future of big data. With Kubernetes, Spark applications will be able to handle huge volumes of data much more reliably, thus giving exact insights and being able to drive decisions with big data.
Submitting a Spark Application to Kubernetes (old style)
Submitting a Spark job to a Kubernetes cluster involves using the spark-submit script with configurations specific to Kubernetes. Here's a step-by-step guide:
Steps:
-
Prepare the Spark Application: Package your Spark application into a JAR file (for Scala/Java) or a Python script.
-
Use
spark-submitto Deploy: Execute thespark-submitcommand with Kubernetes-specific options:./bin/spark-submit \ --master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \ --deploy-mode cluster \ --name spark-app \ --class org.apache.spark.examples.SparkPi \ --conf spark.executor.instances=3 \ --conf spark.kubernetes.container.image=<your-spark-image> \ local:///path/to/your-app.jarReplace:
<k8s-apiserver-host>: Your Kubernetes API server host.<k8s-apiserver-port>: Your Kubernetes API server port.<your-spark-image>: The Docker image containing Spark.local:///path/to/your-app.jar: Path to your application JAR within the Docker image.
Key Configurations:
--master: Specifies the Kubernetes API URL.--deploy-mode: Set toclusterto run the driver inside the Kubernetes cluster.--name: Names your Spark application.--class: Main class of your application.--conf spark.executor.instances: Number of executor pods.--conf spark.kubernetes.container.image: Docker image for Spark pods.
For more details, refer to the Apache Spark Documentation on Running on Kubernetes.
2. Creating a Custom Docker Image for Spark
Building a custom Docker image allows you to package your Spark application and its dependencies, ensuring consistency across environments.
Steps:
-
Create a Dockerfile: Define the environment and dependencies.
# Use the official Spark base image FROM spark:3.5.3 # Set environment variables ENV SPARK_HOME=/opt/spark ENV PATH=$PATH:$SPARK_HOME/bin # Copy your application JAR into the image COPY your-app.jar $SPARK_HOME/examples/jars/ # Set the entry point to run your application ENTRYPOINT ["spark-submit", "--class", "org.apache.spark.examples.SparkPi", "--master", "local[4]", "/opt/spark/examples/jars/your-app.jar"]In this Dockerfile:
FROM spark:3.5.3: Uses the official Spark image as the base.ENV: Sets environment variables for Spark.COPY: Adds your application JAR to the image.ENTRYPOINT: Defines the default command to run your Spark application.
-
Build the Docker Image: Use Docker to build your image.
docker build -t your-repo/your-spark-app:latest .Replace
your-repo/your-spark-appwith your Docker repository and image name. -
Push the Image to a Registry: Upload your image to a Docker registry accessible by your Kubernetes cluster.
docker push your-repo/your-spark-app:latest
While using spark-submit is a common method for deploying Spark applications, it may not be the most efficient approach for production environments. Manual submissions can lead to inconsistencies and are challenging to integrate into automated workflows. To enhance efficiency and maintainability, leveraging Ilum's REST API is recommended.
Automating Spark Deployments with Ilum's REST API
Ilum offers a robust RESTful API that enables seamless interaction with Spark clusters. This API facilitates the automation of job submissions, monitoring, and management, making it an ideal choice for Continuous Integration/Continuous Deployment (CI/CD) pipelines.
Benefits of Using Ilum's REST API:
- Automation: Integrate Spark job submissions into CI/CD pipelines, reducing manual intervention and potential errors.
- Consistency: Ensure uniform deployment processes across different environments.
- Scalability: Easily manage multiple Spark clusters and jobs programmatically.
Example: Submitting a Spark Job via Ilum's REST API
To submit a Spark job using Ilum's REST API, you can make an HTTP POST request with the necessary parameters. Here's a simplified example using curl:
curl -X POST https://<ilum-server>/api/v1/job/submit \
-H "Content-Type: multipart/form-data" \
-F "name=example-job" \
-F "clusterName=default" \
-F "jobClass=org.apache.spark.examples.SparkPi" \
-F "jars=@/path/to/your-app.jar" \
-F "jobConfig=spark.executor.instances=3;spark.executor.memory=4g"
In this command:
name: Specifies the job name.clusterName: Indicates the target cluster.jobClass: Defines the main class of your Spark application.jars: Uploads your application JAR file.jobConfig: Sets Spark configurations, such as the number of executors and memory allocation.
For detailed information on the API endpoints and parameters, refer to the Ilum API Documentation.
Enhancing Efficiency with Interactive Spark Jobs
Beyond automating job submissions, transforming Spark jobs into interactive microservices can significantly optimize resource utilization and response times. Ilum supports the creation of long-running interactive Spark sessions that can process real-time data without the overhead of initializing a new Spark context for each request.
Advantages of Interactive Spark Jobs:
- Reduced Latency: Eliminates the need to start a new Spark context for every job, leading to faster execution.
- Resource Optimization: Maintains a persistent Spark context, allowing for efficient resource management.
- Scalability: Handles multiple requests concurrently within the same Spark session.
To implement an interactive Spark job with Ilum, you can define a Spark application that listens for incoming data and processes it in real-time. This approach is particularly beneficial for applications requiring immediate data processing and response.
For a comprehensive guide on setting up interactive Spark jobs and optimizing your Spark cluster, refer to Ilum's blog post: How to Optimize Your Spark Cluster with Interactive Spark Jobs.
By integrating Ilum's REST API and adopting interactive Spark jobs, you can streamline your Spark workflows, enhance automation, and achieve a more efficient and scalable data processing environment.
Advantages of Using Ilum to run Spark on Kubernetes
Ilum is equipped with an intuitive UI and a resilient API to scale and handle Spark clusters, configuring a couple of Spark applications from one interface. Here are a few great features in that regard:
- Ease of Use: Ilum simplifies Spark configuration and management on Kubernetes with an intuitive Spark UI, eliminating complex setup processes.
- Quick Deployment: Setup, deploy, and scale Spark clusters in minutes to speed up the time to execution and testing applications right away.
- Scalability: Using the Kubernetes API, easily scale Spark clusters up or down to meet your data processing needs, ensuring optimal resource utilization.
- Modularity: Ilum comes with a modular framework that allows users to choose and combine different components such as Spark History Server, Apache Jupyter, Minio, and much more.
Migrating from Apache Hadoop Yarn
Now that Apache Hadoop Yarn is in deep stagnation, more and more organizations are looking toward migrating from Yarn to Kubernetes. This is attributed to several reasons, but most common is that Kubernetes provides a more resilient and flexible platform in matters of managing Big Data workloads.
Generally, it is difficult to carry out a platform migration of the data processing platform from Apache Hadoop Yarn to any other. There are many factors to consider when such a switch is made—compatibility of data, speed, and cost of processing. However, it would come smoothly and successfully if the procedure is well planned and executed.
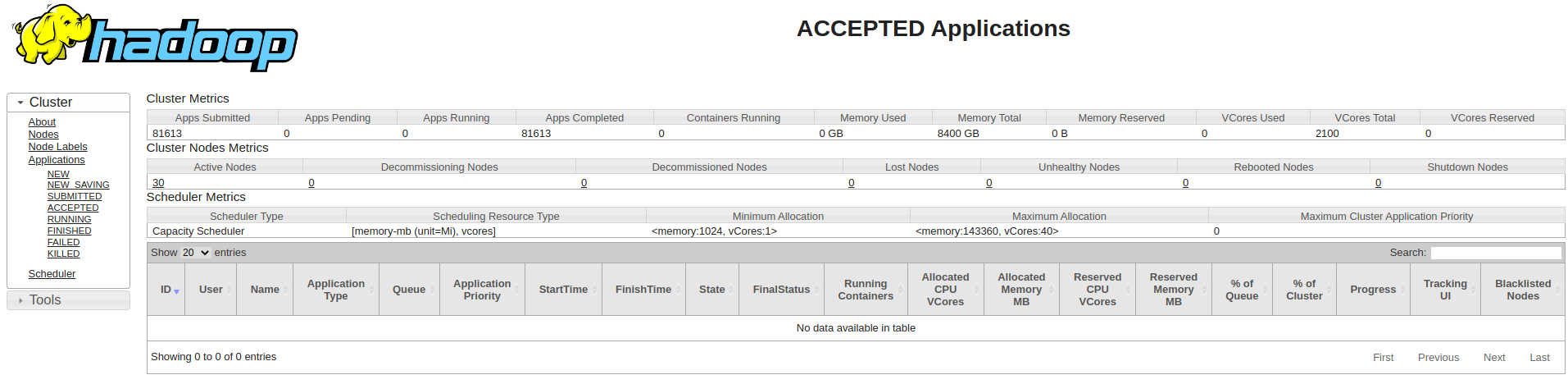
Kubernetes is pretty much a natural fit when it comes to Big Data workloads because of its inherent ability to be able to scale horizontally. But, with Hadoop Yarn, you are limited to the number of nodes in your cluster. You can increase and reduce the number of nodes inside a Kubernetes cluster on demand.
It also allows features which are not available in Yarn, for instance: self-healing and horizontal scaling.
Time to make the Switch to Kubernetes?
As the world of big data continues to evolve, so do the tools and technologies used to manage it. For years, Apache Hadoop YARN has been the de facto standard for resource management in big data environments. But with the rise of containerization and orchestration technologies like Kubernetes, is it time to make the switch?
Kubernetes has been gaining popularity as a container orchestration platform, and for good reason. It's flexible, scalable, and relatively easy to use. If you're still using traditional VM-based infrastructure, now might be the time to make the switch to Kubernetes.
If you're working with containers, then you should definitely care about Kubernetes. It can help you manage and deploy your containers more effectively, and it's especially useful if you're working with a lot of containers or if you're deploying your containers to a cloud platform.
Kubernetes is also a great choice if you're looking for an orchestration tool that's backed by a major tech company. Google has been using Kubernetes for years to manage its own containerized applications, and they've invested a lot of time and resources into making it a great tool.
There is no clear winner in the YARN vs. Kubernetes debate. The best solution for your organization will depend on your specific needs and use cases. If you are looking for a more flexible and scalable resource management solution, Kubernetes is worth considering. If you need better support for legacy applications, YARN may be a better option.
Whichever platform you choose, Ilum can help you get the most out of it. Our platform is designed to work with both YARN and Kubernetes, and our team of experts can help you choose and implement the right solution for your organization.
Managed Spark cluster
A managed Spark cluster is a cloud-based solution that makes it easy to provision and manage Spark clusters. It provides a web-based interface for creating and managing Spark clusters, as well as a set of APIs for automating cluster management tasks. Managed Spark clusters are often used by data scientists and developers who want to quickly provision and manage Spark clusters without having to worry about the underlying infrastructure.
Ilum provides the ability to create and manage your own spark cluster, which can be run in any environment, including cloud, on-premises, or a mixture of both.

The Pros of Apache Spark on Kubernetes
There has been some debate about whether Apache Spark should run on Kubernetes.
Some people argue that Kubernetes is too complex and that Spark should continue to run on its own dedicated cluster manager or stay in the cloud. Others argue that Kubernetes is the future of big data processing and that Spark should embrace it.
We are in the latter camp. We believe that Kubernetes is the future of big data processing and that Apache Spark should run on Kubernetes.
The biggest benefit of using Spark on Kubernetes is that it allows for much easier scaling of Spark applications. This is because Kubernetes is designed to handle deployments of large numbers of concurrent containers. So, if you have a Spark application that needs to process a lot of data, you can simply deploy more containers to the Kubernetes cluster to process the data in parallel. This is much easier than setting up a new Spark cluster on EMR each time you need to scale up your processing. You can run it on any cloud platform (AWS, Google Cloud, Azure, etc.) or on-premises. This means that you can easily move your Spark applications from one environment to another without having to worry about changing your cluster manager.
Another enormous benefit is that it allows for more flexible workflows. For example, if you need to process data from multiple sources, you can easily deploy different containers for each source and have them all processed in parallel. This is much easier than trying to manage a complex workflow on a single Spark cluster.
Kubernetes has several security features that make it a more attractive option for running Spark applications. For example, Kubernetes supports role-based access control, which allows you to fine-tune who has access to your Spark cluster.
So there you have it. These are just some of the reasons why we believe that Apache Spark should run on Kubernetes. If you're not convinced, we encourage you to try it out for yourself. We think you'll be surprised at how well it works.
Additional Resources
- Check how to install Minikube
- Kubernetes Documentation
- Ilum Official Website
- Ilum Official Documentation
- Ilum Helm Chart
Conclusion
Ilum simplifies the process of installing and managing Apache Spark on Kubernetes, making it an ideal choice for both beginners and experienced users. By following this guide, you’ll have a functional Spark cluster running on Kubernetes in no time.